File fragment reorganization recovery method based on XFS file system
Editor's Note: With the continuous development of data recovery technology, the logical layer recovery technology based on disk data is increasingly perfect, but currently there is a huge challenge in the logic layer recovery technology, that is, when deleting files in the state of multiple fragments, the data Restructuring recovery will become very difficult. In this issue, the scientific research personnel of the Sichuan Provincial Key Laboratory of Data Recovery will use the XFS file system to recover the fragments after the files are hashed. Reorganization recovery method.
First, the XFS file system introduction
XFS was originally a high-performance log file system developed by Silicon Graphics, Inc. in the early 1990s. XFS is very scalable and very robust, and SGI ported it to Linux. It is a 64-bit file system.
The XFS file system has good data integrity and can guarantee the consistency of the file system data in the event of power failure and operating system crash. If the file system starts the log function, the files on the disk will no longer be damaged due to unexpected situations. The system can recover the contents of the disk file for a certain period of time according to the recorded log, which is independent of the number of files stored on the file system and the amount of data. In addition, XFS is a full 64-bit file system that supports millions of Tbytes of storage. Support for mega files and small files is outstanding and supports a very large number of directories. The maximum supported file size is 263 = 9 exabytes.
Second, XFS file storage principle
By analyzing the XFS file system storage principle, it is found that the allocation group is the most abstract concept of XFS. The XFS file system is internally divided into multiple "allocation groups" (AG), which are isometric linear storage areas in the file system. Each allocation group manages its own inode and remaining space. Files and folders can span distribution groups. This mechanism provides scalability and parallelism for XFS—multiple threads and processes can perform I/O operations in parallel on the same file system at the same time. This internal partitioning mechanism, which is brought about by the allocation group, is particularly useful when a file system spans multiple physical devices, making it possible to optimize throughput utilization for lower-level storage components.
After creating an XFS file system on a disk, the disk is formatted into the following format, as shown in Figure 1.

figure 1
The default on CentOS7 is to create 4 AGs. Each AG is equivalent to a separate file system, maintaining its own free space and inode, which mainly includes the following information:
• superblock: Information describing the entire file system.
• Free space management.
• Inode allocation and record management
All metadata information in the AG is recorded in the super block superblock, and the metadata of several cores is:
• blocksize, the size of the block used in the file system, and the number of blocks used by the entire file system to hold data and metadata.
• sectorsize specifies the size of one sector of the underlying disk and the minimum alignment granularity of the data.
• AG_blocks/AG_count, the number of blocks in an AG in the file system, and the number of AGs in the entire file system.
• inodesize/inopblock, which records the size of the inode and the number of inodes in each block.
• logstart/logblocks, if the same disk is used to store the XFS journal, these two values ​​are used to represent the first block in which the journal is stored and the total number of blocks used to store the log.
• icount/ifree, the number of inodes already allocated in the file system and the number of remaining inodes available. This is only maintained in AG Primary's Superblock.
It should be noted that the byte order used in the XFS file system is the big end, and all the metadata information structures in the AG are recorded in the Superblock, as shown in FIG. 2 .

figure 2
When the XFS stores the data file, an extend list is generated to store the block structure number occupied by the file, and the records are sequentially recorded, and the number of the block address and the number of used blocks are included in each record. For the sake of convenience, we will use the XFS file system released by IRIX 5.3 as an example. The basic structure of the file linked list is shown in Figure 3.
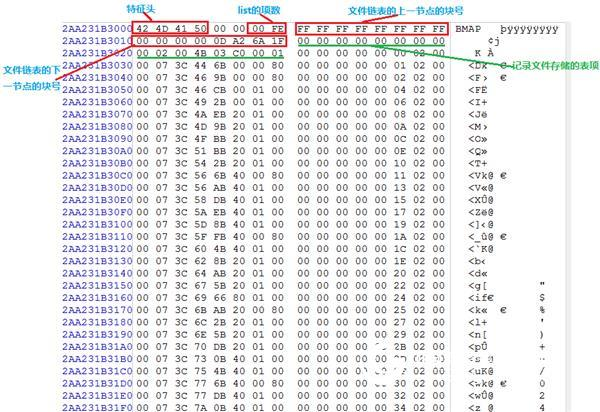
image 3
The length of each file linked list in the XFS file system is the length of one block, and its structure is shown in Figure 4.

Figure 4
The file feature header is 0x424D4150, the length is 4 bytes, the next 2 bytes represent the level of the current file linked list, and the value of the 2 byte record indicates the number of records in the current file linked list, and the addresses of the left and right siblings. Each of them occupies 8 bytes for storage, and the subsequent data is a plurality of record item data, and each record item has a length of 16 bytes. If a record item is not used, its 16-byte length content is used. 00 indicates.
The block address information of the storage file is recorded in each record item, and the structure of each specific record item is as shown in FIG. 5.

Figure 5
The unit of division of the storage structure in the record item is bit (bit). Since the length of each record item is 16 bytes, that is, 16*8=128 bits, the value of 1 bit offset from the start of each record entry is The mark bit of the record item; the offset of 2 bit to 55 bit from the start of each record item is the number of blocks of the relative offset of the block data recorded in the record in the file; the offset from the start of each record entry The value of 56bit~107bit is the block address used by the file, where the information of the address information is recorded in the AG number of the block used by the file and the relative offset number of the block in the AG, where the relative offset of the block in the AG The number of digits occupied by the number in the structure is low, and the value of the length is the value recorded in the XFS file system relative to the start offset of the superblock 0x7 C bytes, thereby calculating the value of the AG number where the block is located. The relative offset of the record entry is 56bit~107bit, and its length is 52. The length of the relative offset number of the block in the AG is offset. The value of the offset from the start of each record is 108bit~128bit. The number of blocks used.
Third, XFS file system fragmentation recovery recovery ideas
Through in-depth analysis of the XFS file system, it is found that when the files are not consecutively allocated during storage, the extend file chain is used to record the file storage information. By comparing the changes before and after the file deletion, it is found that the file inode node information will be cleared after the file is deleted, and the file linked list information will not be lost, as shown in Fig. 6, which provides theoretical support for data recovery.

Image 6
Since XFS stores a data file, it generates a linked list to store the number of the block structure occupied by the file, and records in order, including the number of the block address and the number of blocks used in each record. According to the above feature, the data is searched by quickly locating the linked list of the block number of the storage file, and the data content of the corresponding block address is read according to the information recorded in the linked list, and then the extracted data is performed in the order of the records of the linked list. Splicing and reorganization can realize the fragmentation of the XFS file system. This method not only can quickly and efficiently extract deleted video data, but also splicing and reorganizing the deleted video data.
Fourth, the XFS file system fragment reorganization recovery process
The fragment reorganization recovery method based on the XFS file system is mainly completed by the following processes:
1. Load and parse disk sector information
Load the disk, read the sector information of the super block in the AG in the disk and parse it. The content that needs to be parsed includes the block size, the total number of blocks, the number of blocks included in the AG, and the relative offset value of each block in the AG. Specifically, the superblock is located in the first sector of the AG data, and the value recorded in the offset 0x04~0x07 with respect to the super start address indicates the block size, and the value recorded in the offset 0x08~0x0F with respect to the super start address is represented. The total number of blocks, the value recorded in the offset 0x54~0x57 with respect to the super start address indicates the total number of blocks included in a single AG, and the value recorded in the offset 0x7C with respect to the super start address is indicated in the file linked list entry. The relative offset number of the block at the AG.
2. Matching file linked list structure
Get the size of a single file linked list, which is the value of the block size. The data of the entire hard disk is divided into several blocks according to the block size, and each block is matched with the structure of the file linked list. The structural features of the file linked list include the following features:
Feature 1: The file linked list feature header is 0x424D4150;
Feature 2: The last two bytes of the file linked list feature header indicate the level of the file linked list, where the range of recorded values ​​is 0~255;
Feature 3: The last two bytes of the file linked list level indicate the number of entries in the file linked list, and the value recorded here should be less than the total number of blocks recorded in the super block;
Feature 4: The 8 bytes after the feature 3 indicate the state of the data content before the file recorded by the file linked list, and the value recorded at the place should be less than the total number of blocks recorded in the super block;
Feature 5: 8 bytes after the feature 4 indicates the state of the data content after the file recorded by the file linked list, and the value recorded at the place should be smaller than the total number of blocks recorded in the super block;
3. Analyze the file link structure
First, the feature 4 of 2 is used to judge whether the file recorded by the file linked list contains data before the address recorded in the file linked list. If the value of the address described by feature four in 2 is -1, it means that there is no file data before, and it also indicates that the file chain is the root node of the file storage; if the value of the address described by feature four in 2 is not -1 The value indicates the block number of the file linked list of the file recorded in the file linked list before the address recorded in the file linked list, and jumps to the file linked list structure in the corresponding block number read block, and parses according to the method described in 3. File linked list structure; in the same reason, the file recorded in the file linked list described in feature 5 of the second item contains data after the address recorded in the file linked list; in turn, each record item data in the file linked list is read according to the structural characteristics of the record item. Record the block number of the file data and the number of blocks occupied.
4. Read the corresponding block address data
According to the content analyzed in 3, according to the order recorded in the file linked list, the data content of the block address corresponding to each record item is sequentially read;
5. Reorganize new documents
The data read in 4 is sequentially spliced ​​according to the relationship between the linked list of files recorded in the file linked list and the order of the recorded items, and the data of the block addresses recorded in the items are sequentially spliced ​​into a new file;
6. Traversing the hard disk sector
After parsing the value recorded in a file linked list, continue to search the file linked list structure and judge whether the file linked list is used. If it is used down, if it is not used, it will be parsed. Repeat steps 2 to 5 until traversing. The entire hard disk sector.
Through the above steps, the fragment reorganization recovery of the XFS file system can be realized.
Fourth, the conclusion
In this issue, the researchers in the data recovery Sichuan Key Laboratory introduced a method for quickly extracting and restoring video deletion data based on the XFS file system. This method can not only quickly and efficiently extract and delete video data, but also splicing deleted video data. Reorganization. At present, this method has been applied in products such as efficiency source DRS data recovery system, VIP video surveillance individual soldier system, VIE video all-around extraction system, and has achieved good results.
Women'S Mini Floral Dress,Women'S Solid Bodycon Skirt,Womens Slim Dress,Womens Bodycon Sweater Dress
Hun Yuan Ya Lian Wan Jia Dian Zi Shang Wu You Xian Ze Ren Gong Si , https://www.ylwjastragalus.com